
A not-so-brief intro to K2Nodes
For the past three weeks I have been, on and off, dipping my toes into the confusing world of Slate and K2Nodes. The goal was to simply learn more about the lower levels of the Engine, however, me being me, I needed a more concrete goal to work towards to maintain motivation and focus.
To that end, I decided that I would make two K2Nodes:
- A Node that takes in a UObject Reference, and an FName, then Gets and returns the Variable of the same name found inside the UObject (if it exists).
- A Node that takes in a UObject Reference, an FName, and a Wildcard, then Sets and returns the Variable of the same name found inside the UObject (if it exists).
Both would also return a “bSuccess” boolean for safety.
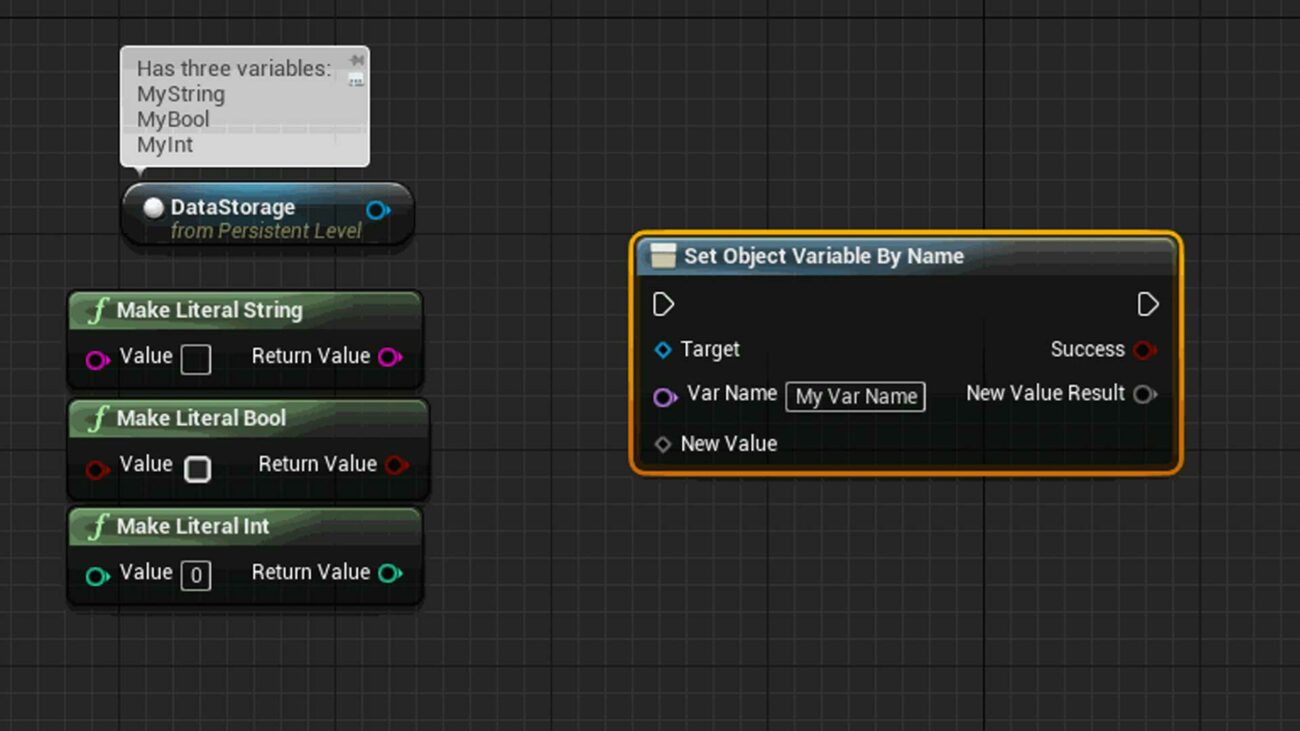
Spoiler alert, here are the two nodes in action:
This blog won’t take you step by step through the process of making these Nodes (though the full code will be provided at the end). Instead, it will attempt to dissect the more important aspects of the K2Nodes and shed some light on their overall structure and conventions. In the end, I’m hoping that my journey will also help you with your own adventures into K2Nodes.
So, the first main question:
What are K2Nodes?
Seems obvious, but it was a hard question to answer coming in blind, and there aren’t many resources online that explain it simply.
In short, a K2Node is a very fancy Blueprint Node that can be used to wrap more advanced and dynamic functionality than your average UFUNCTION. For example, having the inputs and outputs of a Node change depending on other inputs and outputs, or having core functionality of the Node completely change depending on input types. One way to think of it is a Blueprint Node that has two or more functions inside of it; one that takes the inputs, passes it around through N functions, then another function that returns the output, like a subgraph in Blueprints.
You can find Engine K2Nodes in Source/Editor/BlueprintGraph/Classes/ and I highly recommend reading through some time. Two good examples are K2Node_SpawnActorFromClass and K2Node_GetDataTableRow as they have some solid comments as well as fairly straightforward outcomes (not the code though, it is hard to read without getting to know K2Node syntax).
Bringing this back to my intended outcomes, why did I have to use K2Nodes? You can absolutely achieve the same result through normal UFUNCTIONS. However I wanted to be lazy in the most difficult way; rather than having a Node per variable type I wanted a single master Node that does it all.
Initially I tried using a CustomThunk which is how you can accept Wildcards into normal UFUNCTIONS. While there is a lot to learn there, I won’t go into it in this blog – it didn’t do the job as I couldn’t get Wildcard return values. So the only choice was K2Nodes.
So I began digging.
Anatomy of a K2Node
First I had to do some reading on the subject. Here are a few good resources that I initially utilised:
But your most helpful resource, after reading through all those (which you should), is going to be existing Nodes in the Engine, especially a Node that has similar functionality to what you’re looking to achieve. In my case this was K2Node_GetClassDefaults, K2Node_VariableGet and K2Node_VariableSet. And yes, those last two are the Get/Set variable Nodes that are in every Blueprint graph ever.
One thing that became apparent is that there is a solid amount of boilerplate present in all K2Nodes that is responsible for how it looks and behaves. Take these for example:
FText UPSK2Node_SetObjectVarByName::GetNodeTitle(ENodeTitleType::Type TitleType) const
{
return LOCTEXT("SetObjVarByNameK2Node_Title", "Set Object Variable By Name");
}
FText UPSK2Node_SetObjectVarByName::GetTooltipText() const
{
return LOCTEXT("SetObjVarByNameK2Node_Tooltip", "Sets the value of a variable in a provided object. Takes in the target object and the name of the variable to be changed, then sets the value to the provided New Value.");
}
FText UPSK2Node_SetObjectVarByName::GetMenuCategory() const
{
return LOCTEXT("SetObjVarByNameK2Node_MenuCategory", "nfPopulationSystem");
}As you can see, these three functions are simply responsible for giving the Node its name, tooltip, and category. It’s worth noting that they return LOCTEXT types, which is because this is technically Slate code, so the text has to be clean, optimised, and localisable.
Another is this:
virtual void GetMenuActions(FBlueprintActionDatabaseRegistrar& ActionRegistrar) const override;void UPSK2Node_SetObjectVarByName::GetMenuActions(FBlueprintActionDatabaseRegistrar& ActionRegistrar) const
{
Super::GetMenuActions(ActionRegistrar);
UClass* Action = GetClass();
if (ActionRegistrar.IsOpenForRegistration(Action))
{
UBlueprintNodeSpawner* Spawner = UBlueprintNodeSpawner::Create(GetClass());
check(Spawner != nullptr);
ActionRegistrar.AddBlueprintAction(Action, Spawner);
}
}This function adds your K2Node to the right-click context menu in the Blueprint Graph, so it’s quite important.
The other big chunks of boilerplate are these:
//Helpers for getting pins
UEdGraphPin* GetThenPin() const;
UEdGraphPin* GetTargetPin() const;
UEdGraphPin* GetVarNamePin() const;
UEdGraphPin* GetNewValuePin() const;
UEdGraphPin* GetReturnResultPin() const;
UEdGraphPin* GetReturnValuePin() const;These are handy little functions for getting references to all the pins (inputs and outputs) that this Node has. You don’t need these functions, but they do make your life easier. Note that they don’t override anything, so their implementation is up to you. Here’s how I did it:
UEdGraphPin* UPSK2Node_SetObjectVarByName::GetThenPin() const
{
const UEdGraphSchema_K2* K2Schema = GetDefault<UEdGraphSchema_K2>();
UEdGraphPin* Pin = FindPinChecked(UEdGraphSchema_K2::PN_Then);
check(Pin->Direction == EGPD_Output);
return Pin;
}
...
...
UEdGraphPin* UPSK2Node_SetObjectVarByName::GetNewValuePin() const
{
UEdGraphPin* Pin = FindPin(FGetPinName::GetNewValuePinName());
check(Pin == NULL || Pin->Direction == EGPD_Input);
return Pin;
}
UEdGraphPin* UPSK2Node_SetObjectVarByName::GetReturnResultPin() const
{
UEdGraphPin* Pin = FindPin(FGetPinName::GetOutputResultPinName());
check(Pin == NULL || Pin->Direction == EGPD_Output);
return Pin;
}Note the lack of a function to Get the Exec pin. This is because it is already declared in the super K2Node.h and doesn’t need overriding.
Last up on our tour of boilerplates is the handling and storing of FNames. In my travels I came across three different methods for caching FText/FNames, one of which has a clear mechanical purpose, while the other two are more straightforward but less versatile.
We cache these because, according to a handy comment in K2Node_GetDataTableRow:
/** Constructing FText strings can be costly … */
Since a lot of Slate stuff is run on UI Tick, it is wise to minimise overhead where possible.
The first method is as follows:
namespace FSetterFunctionNames
{
static const FName FloatSetterName(GET_FUNCTION_NAME_CHECKED(UPSData, SetFloatByName));
static const FName IntSetterName(GET_FUNCTION_NAME_CHECKED(UPSData, SetIntByName));
static const FName Int64SetterName(GET_FUNCTION_NAME_CHECKED(UPSData, SetInt64ByName));
...
...
};In this example I am returning the FName for my Setter Functions in a Blueprint Function Library. These are just normal UFUNCTIONs.
This method can be accessed with FSetterFunctionNames::FloatSetterName and is pretty straightforward.
The second method:
struct FGetPinName
{
static const FName& GetTargetPinName()
{
static const FName TargetPinName(TEXT("Target"));
return TargetPinName;
}
static const FName& GetVarNamePinName()
{
static const FName VarNamePinName(TEXT("VarName"));
return VarNamePinName;
}
...
...
};Very similar, this method uses a Struct in place of the Namespace, and static const functions in place of static const variables. You would access via FGetPinName::GetTargetPinName() which is pretty much the same as the Namespace method.
I could be wrong (prefix that onto every statement in this blog), but I consider these two approaches interchangeable, and it comes down to your own preferences and coding standards.
The last method is this:
FNodeTextCache CachedNodeTitle;CachedNodeTitle.SetCachedText(FText::Format("Get Row From {1}"), DataTablePin->DefaultObject->GetName(), this);I didn’t end up using this approach as I only came across it after the fact, but given it utilises an Engine Struct I believe it would be the most reliable. It also allows for dynamic cached FTexts, which is rad because your Node title (in this example) can change depending on input values (which is what the GetDataTableRow Node does, check it out). This means that it is only constructing the new FText once when needed, rather than every tick.
Those are the bulk of the boilerplate. Next we’ll move onto the main functions you need to call to make the magic happen.
Main functions
There are many, many functions in the super K2Node class, that do a host of different things. You won’t need most of them most of the time, but there are some that you will need all the time, like these two main functions (in addition to those listed above) that you will always need to override:
virtual void AllocateDefaultPins() override;This function is where you add input and output pins to the Node, at creation.
virtual void ExpandNode(class FKismetCompilerContext& CompilerContext, UEdGraph* SourceGraph) override;This function is what runs when you compile and run the Node, so it can be considered the Runtime functionality of the Node, rather than the Editor functionality.
Let’s look at my definitions for the Get Node, first AllocateDefaultPins()
void UPSK2Node_SetObjectVarByName::AllocateDefaultPins()
{
const UEdGraphSchema_K2* K2Schema = GetDefault<UEdGraphSchema_K2>();
/*Create our pins*/
// Execution pins
CreatePin(EGPD_Input, UEdGraphSchema_K2::PC_Exec, UEdGraphSchema_K2::PN_Execute);
CreatePin(EGPD_Output, UEdGraphSchema_K2::PC_Exec, UEdGraphSchema_K2::PN_Then);
//Input
UEdGraphNode::FCreatePinParams PinParams;
PinParams.bIsReference = true;
UEdGraphPin* InTargetPin = CreatePin(EGPD_Input, UEdGraphSchema_K2::PC_Object, UObject::StaticClass(), FGetPinName::GetTargetPinName(), PinParams);
UEdGraphPin* InVarNamePin = CreatePin(EGPD_Input, UEdGraphSchema_K2::PC_Name, FGetPinName::GetVarNamePinName());
K2Schema->SetPinAutogeneratedDefaultValue(InVarNamePin, FName("My Var Name").ToString());
UEdGraphPin* InNewValuePin = CreatePin(EGPD_Input, UEdGraphSchema_K2::PC_Wildcard, FGetPinName::GetNewValuePinName(), PinParams);
//Output
UEdGraphPin* OutValidPin = CreatePin(EGPD_Output, UEdGraphSchema_K2::PC_Boolean, FGetPinName::GetOutputResultPinName());
K2Schema->SetPinAutogeneratedDefaultValueBasedOnType(OutValidPin);
UEdGraphPin* OutNewValuePin = CreatePin(EGPD_Output, UEdGraphSchema_K2::PC_Wildcard, FGetPinName::GetOutputValuePinName());
Super::AllocateDefaultPins();
}As you can see, the CreatePin() function is the weightlifter in this case. Calling it will add and register the resulting Pin to the K2Node. No need to store as a variable unless you need to do something to it, such as setting its default value (its value when it isn’t connected to another pin).
The only other fancy part is creating and passing CreatePin() an FCreatePinParams for making slightly more advanced Pins, in this case a Pass by Reference. This FCreatePinsParam is then passed as an argument to the CreatePin() function.
That’s all there is to this function, at this level.
Let’s have a look at ExpandNode()
void UPSK2Node_SetObjectVarByName::ExpandNode(class FKismetCompilerContext& CompilerContext, UEdGraph* SourceGraph)
{
Super::ExpandNode(CompilerContext, SourceGraph);
UFunction* BlueprintFunction = FindSetterFunctionByType(GetNewValuePin()->PinType);
if (!BlueprintFunction)
{
CompilerContext.MessageLog.Error(*LOCTEXT("InvalidFunctionName", "The function has not been found.").ToString(), this);
return;
}
UK2Node_CallFunction* CallFunction = CompilerContext.SpawnIntermediateNode<UK2Node_CallFunction>(this, SourceGraph);
CallFunction->SetFromFunction(BlueprintFunction);
CallFunction->AllocateDefaultPins();
CompilerContext.MessageLog.NotifyIntermediateObjectCreation(CallFunction, this);
//Input
CompilerContext.MovePinLinksToIntermediate(*FindPin(FGetPinName::GetTargetPinName()), *CallFunction->FindPinChecked(TEXT("Target")));
CompilerContext.MovePinLinksToIntermediate(*FindPin(FGetPinName::GetVarNamePinName()), *CallFunction->FindPinChecked(TEXT("VarName")));
CompilerContext.MovePinLinksToIntermediate(*FindPin(FGetPinName::GetNewValuePinName()), *CallFunction->FindPinChecked(TEXT("NewValue")));
//Output
CompilerContext.MovePinLinksToIntermediate(*FindPin(FGetPinName::GetOutputValuePinName()), *CallFunction->FindPinChecked(TEXT("OutValue")));
CompilerContext.MovePinLinksToIntermediate(*FindPin(FGetPinName::GetOutputResultPinName()), *CallFunction->GetReturnValuePin());
//Exec pins
UEdGraphPin* NodeExec = GetExecPin();
UEdGraphPin* NodeThen = FindPin(UEdGraphSchema_K2::PN_Then);
UEdGraphPin* InternalExec = CallFunction->GetExecPin();
CompilerContext.MovePinLinksToIntermediate(*NodeExec, *InternalExec);
UEdGraphPin* InternalThen = CallFunction->GetThenPin();
CompilerContext.MovePinLinksToIntermediate(*NodeThen, *InternalThen);
//After we are done we break all links to this node (not the internally created one)
BreakAllNodeLinks();
}That’s a bit more than the other, so let’s break it down a bit.
After calling the super I call one of my own functions UFunction* BlueprintFunction = FindSetterFunctionByType(GetNewValuePin()->PinType); which simply returns an appropriate Set function based on the FPinType argument, so if the Input Pin is a Boolean, it returns the SetBooleanByName() function reference by accessing the FSetterFunctionNames namespace mentioned earlier.
Once we have stored that UFUNCTION and confirmed it exists, we then make a UK2Node_CallFunction Node. This can be thought of as a basic K2Node wrapper for any function, which generates its own Input and Output pins based on the declaration of the UFUNCTION it is wrapped around. So in this section:
CallFunction->SetFromFunction(BlueprintFunction);
CallFunction->AllocateDefaultPins();CallFunction is the K2Node_CallFunction, and we pass it our stored UFUNCTION, then run its AllocateDefaultPins() to get it set up.
Now we’re ready to simply plug the inputs and outputs from our own K2Node to the K2Node_CallFunction “Node” that we have spawned.
//Input
CompilerContext.MovePinLinksToIntermediate(*FindPin(FGetPinName::GetTargetPinName()), *CallFunction->FindPinChecked(TEXT("Target")));
CompilerContext.MovePinLinksToIntermediate(*FindPin(FGetPinName::GetVarNamePinName()), *CallFunction->FindPinChecked(TEXT("VarName")));
CompilerContext.MovePinLinksToIntermediate(*FindPin(FGetPinName::GetNewValuePinName()), *CallFunction->FindPinChecked(TEXT("NewValue")));
//Output
CompilerContext.MovePinLinksToIntermediate(*FindPin(FGetPinName::GetOutputValuePinName()), *CallFunction->FindPinChecked(TEXT("OutValue")));
CompilerContext.MovePinLinksToIntermediate(*FindPin(FGetPinName::GetOutputResultPinName()), *CallFunction->GetReturnValuePin());
//Exec pins
UEdGraphPin* NodeExec = GetExecPin();
UEdGraphPin* NodeThen = FindPin(UEdGraphSchema_K2::PN_Then);
UEdGraphPin* InternalExec = CallFunction->GetExecPin();
CompilerContext.MovePinLinksToIntermediate(*NodeExec, *InternalExec);
UEdGraphPin* InternalThen = CallFunction->GetThenPin();
CompilerContext.MovePinLinksToIntermediate(*NodeThen, *InternalThen);To explain; the UFUNCTION that I have stored has five plus two “Pins”:
Exec: Which is the input that runs the function, with no real comparison in raw c++
Then: Which is the output signal once the function has finished running, again with no direct raw c++ comparison.
Then the actual arguments:
Target: A UObject* input argument.
VarName: An FName input argument.
NewValue: The new value to be input. So if we are modifying a boolean value this would be a bool, if it’s a float value it would be a float, etc.
OutValue: A const output value, with the same type as NewValue.
Return: The default return type for the function, as declared in the c++, which for all of these was a Boolean, ie bSuccess.
Here is it’s declaration (for the boolean version) for reference:
UFUNCTION(BlueprintCallable, BlueprintInternalUseOnly)
static bool SetBoolByName(UObject* Target, FName VarName, bool NewValue, bool &OutValue);Looking back + moving forward
Looking back, K2Nodes aren’t nearly as complex as they seem, and it is more a matter of understanding what types of pins and functions work best for what you are trying to achieve. I’ve glossed over a few functions of importance, but the broad strokes are there.
If you want to check out the full, bug-ridden and insufficiently commented code for my two Nodes, click here. It’s worth noting that currently my Nodes don’t handle structs and enums. They’re a little more complex and so will take some more work. I will continue to tinker with them and improve them as my understanding grows.
Otherwise, if you have any questions, get in touch with me on Twitter via @_nFerrar. And, of course, subscribe below to get more tutorials and updates from the team.
Happy coding!






